
The point of this post is not to look at it in the general sense of the differences. There are many articles on the internet, and one can google for that. The point is to put it into the context of exploiting the massive difference, which enables it to replace a data warehouse. It will lay the foundation for an organization to adopt advanced technologies such as AI, Data Mining, ML, and eventually predictive analysis.
| Criteria | Lakes | Warehouses | Lake Advantage |
|---|---|---|---|
| Data Type |
|
Structured only | Most corporate data is structured. So this point is not that significant but is still a difference |
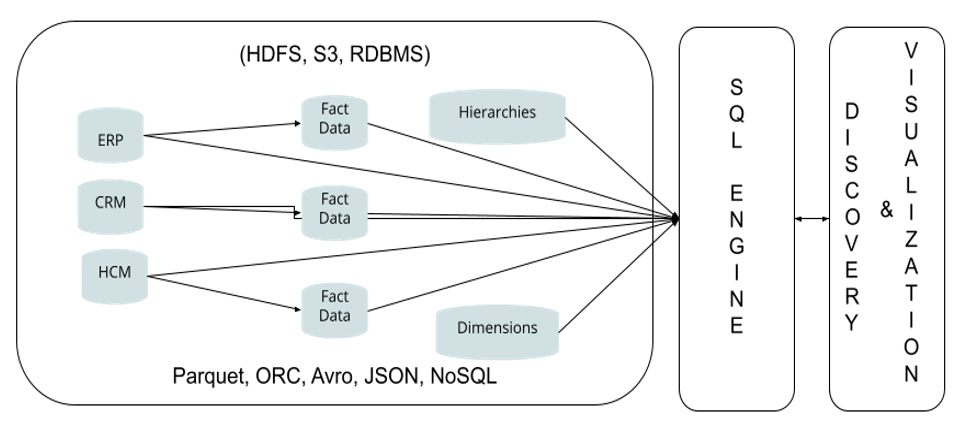
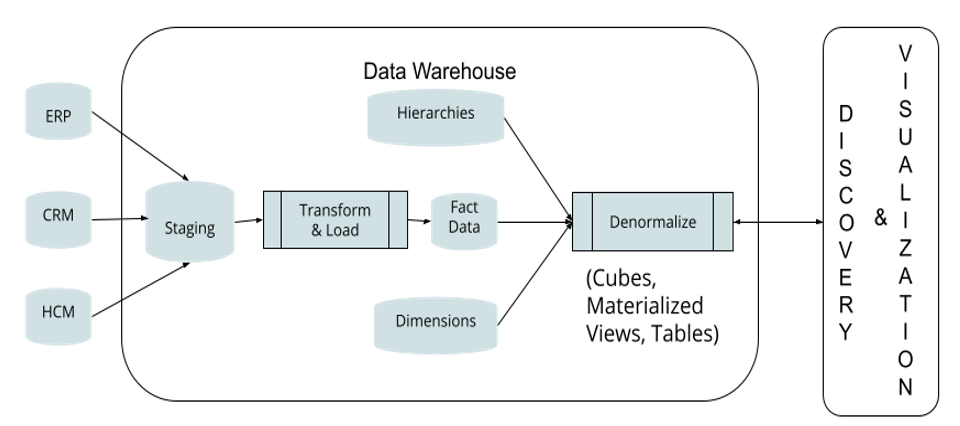
| Transformation | None to minimal (ideally none) | Transformed | Consume data in its raw form as soon as its ingested in the lake |
| Staging | None | Always | Eliminate staging tables as there is no need for transformation |
| Latency | Potentially zero. Data is immediately available for consumption | Usually, one day or more as ETL and rebuilds are batch jobs | The two above differences eliminate latency |
| Fact Tables | Raw | Built with Foreign-key references to Dimension level tables | The FK’s are the same that exist in the source system as the fact tables |
| Business Views | None. Left to data discovery and visualization layer | Static, pre-defined | There are no universe or business area definitions required before they are available for discovery and consumption |
| End-points for Discovery and Visualization Layer | Many | Usually one | There are no constraints of either hardware or software to restrict the lakes to a single store, such as a back-end OLAP DB |
| Ongoing Changes | Easy | Complex & expensive | There is no need to make changes to ETL, rebuild universes and business areas |
As you can see, other than the first difference, all others enable a massive ability to provide significant benefits:
| Benefits | Why? |
|---|---|
| Real-Time Analytics | Since there is no need to transform data, it is consumable immediately |
| Adaptability | Multiple data formats for optimized query consumption (rows and columns) |
| Reduced costs for scalability, high availability, disaster recovery, and ongoing maintenance | Unconstrained by expensive hardware and software licenses. Options are available for vendor-supported software, albeit much cheaper than proprietary software. Cheaper to make changes and enhancements |
| Performance | Leverage high-performance modern SQL engine to execute queries. They scale linearly with the addition of computing power |
| Enhanced end-user experience | Lightweight components leverage the heavy lifting done by a highly efficient distributed SQL Engine. There is no need to have intermediate UI caching or servers |

Call 866-531-9587 / Fill out the contact form.

